Di era digital sekarang ini, berbagai data dapat ditemukan dengan mudah di internet. Sebagai seorang data analis dan scientist, hal ini tentu menjadi kabar baik karena dapat meningkatkan kualitas model dan mempertajam hasil analisis. Tapi bagaimana jika data tersebut tersedia dalam website yang diperuntukan untuk dibaca melalui browser? Beberapa website memang menyediakan fasilitas untuk menyimpan data (seperti Twitter melalui API public), tapi sayangnya sebagian besar tidak. Salah satu cara yang umum dilakukan adalah dengan membuka satu-per-satu halaman web lalu “copy-paste” data secara manual - tentunya akan menyita banyak waktu jika data sangat banyak. Web scraping adalah teknik yang lebih “smart” untuk otomatisasi proses copy-paste ini. Selain agar lebih efisien, tujuan utama dari web scraping sebenarnya adalah memanfaatkan struktur atau pola dari suatu laman web untuk mengekstrak dan menyimpan data dalam format yang diinginkan untuk dianalisis lebih lanjut.
Secara teknis, ada beberapa pendekatan untuk melakukan web scraping, diantaranya:
- Parsing HTML dari suatu laman web menggunakan CSS selector. Merupakan cara yang umum digunakan dan biasanya dapat dilakukan untuk banyak website.
- Schema JSON linked data dan JavaScript variable.
- XHR (XML HTTP Requests)
Melalui artikel ini mari kita pelajari yang pertama: scraping dengan cara parsing HTML dari suatu laman HTML. Tools yang akan digunakan adalah R dengan package rvest. Agar lebih menarik, saya menggunakan contoh real berupa data top-scorers Liga Inggris dari halaman BBC Sport.
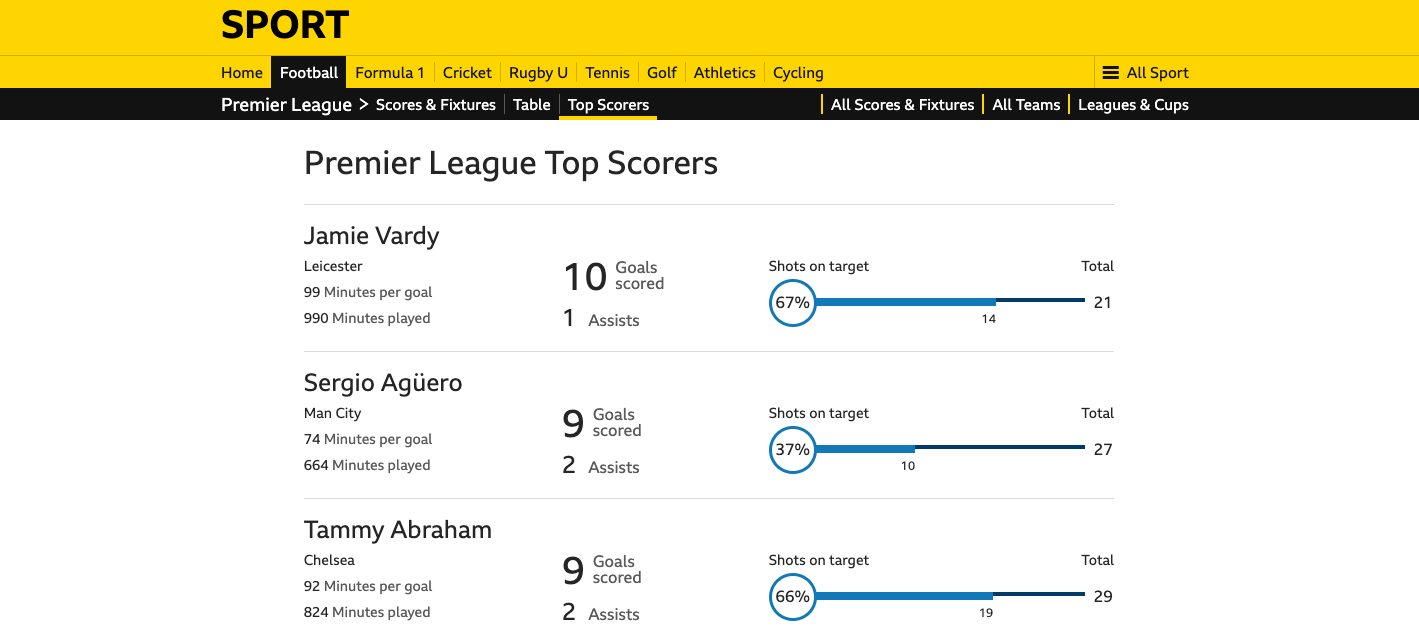
Catatan: Web scraping merupakan salah satu teknik yang sangat bermanfaat untuk mendapatkan data dari internet, tetapi dapat menyebabkan masalah bagi beberapa website. Untuk itu, proses web scraping harus dilakukan dengan penuh pertimbangan dan etika. Sebelum melakukan web scraping sebaiknya periksa dulu apakah website mempunyai file robots.txt? Jika iya, lihat apakah diizinkan untuk melakukan scraping pada halaman yang kita inginkan. File robots.txt dapat diakses di nama-domain/robots.txt, misalnya https://www.bbc.com/robots.txt.
Package rvest
Package rvest ditulis oleh Hadley Wickham dari RStudio. Package ini mempunyai fungsi yang serupa dengan library beautiful soup pada Python, yaitu untuk web scraping. Langkah pertama, tentu saja, install dan load package rvest.
install.packages("rvest")
library(rvest)
Inspect and scrape
Proses scraping kita mulai dengan membaca file HTML dari halaman website dengan menggunakan fungsi read_html.
url <- "https://www.bbc.com/sport/football/premier-league/top-scorers"
html <- read_html(url)
Selanjutnya, melalui browser kita identifikasi “letak” dari data yang akan kita ekstrak. Pada contoh ini, kita akan ekstrak list top scorers termasuk detailnya meliputi:
- player name
- team
- total goal scored
- minutes played
- minutes per goal
- total assists
- total shots on goal target
- total shots
- percentage on target
Caranya, buka URL top-scorers melalui browser (misal pada contoh ini saya menggunakan Google Chrome). Klik kanan, klik Inspect lalu klik tab Element. Klik icon tanda panah di bagian kiri-atas, lalu arahkan kursor pada teks/element yang akan kita ekstrak. Sebagai contoh untuk mengekstrak nama pemain, bisa arahkan kursor pada salah satu nama pemain.
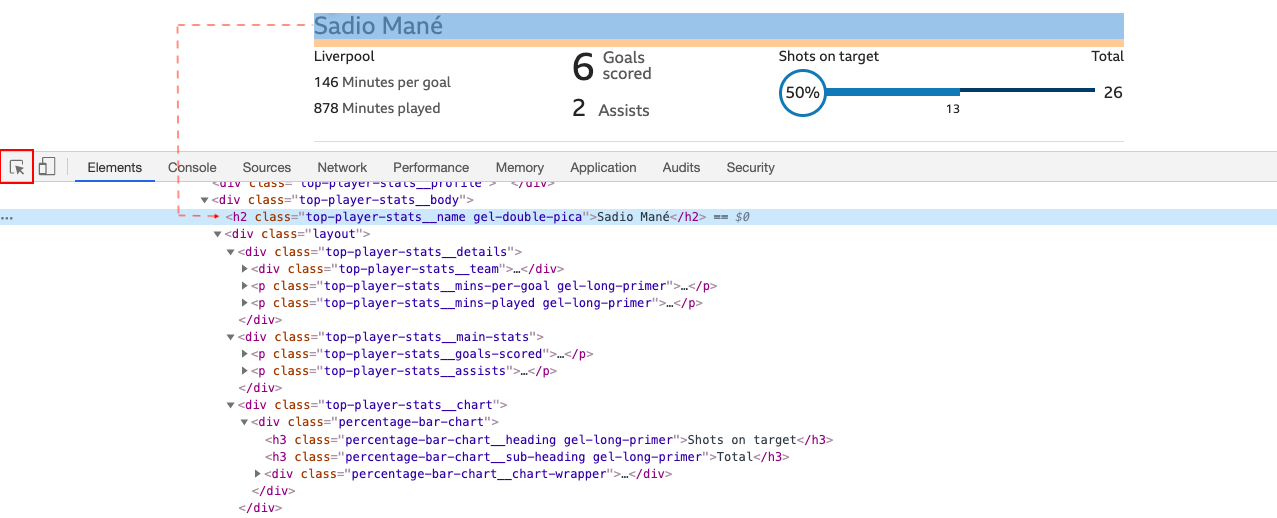
Secara otomatis Chrome akan meng-highlight baris element HTML di mana teks itu berada, yaitu:
<h2 class="top-player-stats__name gel-double-pica">Sadio Mané</h2>
Yang kita perlukan adalah CSS selectors atau XPath dari element tersebut. CSS selector biasanya ditandai dengan class, id, dan sebagainya (referensi). CSS selector untuk nama pemain adalah top-player-stats__name. Karena merupakan class, tambahkan titik sebelum huruf pertama, sehingga menjadi .top-player-stats__name.
Kembali ke R. Setelah mengetahui selector-nya, kita bisa mengekstrak informasi nama pemain dengan fungsi html_nodes (jika hanya satu pemain saja bisa menggunakan html_node) dan html_text untuk mengambil teksnya. Parameter trim = TRUE berguna untuk menghilangkan space sebelum/setelah teks.
html %>%
html_nodes(".top-player-stats__name") %>%
html_text(trim = TRUE)
Dengan cara seperti di atas, kita bisa mengekstrak nama team dengan selector .top-player-stats__team
html %>%
html_nodes(".top-player-stats__team") %>%
html_text(trim = TRUE)
Membuat fungsi scraping
Karena proses ekstraksi data merupakan pengulangan (dengan mengganti CSS selector), sangat disarankan untuk dibuat sebagai fungsi.
scrape <- function(selector, html){
html %>%
html_nodes(selector) %>%
html_text(trim = TRUE)
}
Sehingga untuk mendapatkan total goals scored cukup dengan perintah
scrape(".top-player-stats__goals-scored-number", html)
Selanjutnya kita iterasi fungsi scrape untuk seluruh selector. Iterasi bisa menggunakan fungsi sapply/lapply.
selector <- c(".top-player-stats__name",
".top-player-stats__team",
".top-player-stats__goals-scored-number",
".top-player-stats__mins-played",
".top-player-stats__mins-per-goal",
".top-player-stats__assists",
".shots-on-goal-total",
".shots-total",
".percentage-goals-on-target")
top_scorers <- sapply(selector, scrape, html)
str(top_scorers)
Clean up! Proses scraping sudah selesai dan hasilnya disimpan dalam matriks top-scorers. Matriks tersebut dapat kita ubah menjadi data frame dan beri nama yang tepat untuk setiap kolom.
top_scorers <- as.data.frame(top_scorers)
col_names <- c("name",
"team",
"total_goal",
"mins_played",
"mins_per_goal",
"assists",
"shots_on_goal",
"shots_total",
"percent_on_target")
names(top_scorers) <- col_names
top_scorers
Last but not least…
Tutorial ini hanya menggunakan tiga fungsi rvest. Tentu saja, ada fungsi-fungsi lain yang bisa digunakan sesuai keperluan, di antaranya:
html_attrdanhtml_httrs: untuk ekstrak atribut, teks dan taghtml_table: untuk parsing tabel HTML menjadi data framehtml_form: parsing form- Dan lain-lain.
Sebagai catatan tambahan terkait dengan web scraping:
- Scraping dengan rvest hanya bisa digunakan untuk web statis (artinya konten/data yang akan diekstrak berada dalam file HTML). Untuk web dinamis di mana data di-generate oleh JavaScript, misalnya, tidak cukup menggunakan rvest.
- Scraping hanya efektif apabila HTML terstruktur dengan baik. Bisa dibayangkan jika nama-nama pemain pada contoh di atas berada pada class yang berbeda?
- Jika tersedia, gunakan API (applicaton program interface) dan hindari scraping.
- Seperti telah saya sampaikan sebelumnya, lakukan scraping dengan penuh “etika”. Jangan sampai membebani website.
Selamat menambang data! Semoga bermanfaat.
Pendekatan scraping lainnya akan kita pelajari pada artikel terpisah.